- 2.1 分词
- 2.1.1 基于空格与标点符号的分词
- 2.1.2 基于正则表达式的分词
- 2.1.3 词间不含空格的语言的分词
- 2.1.4 基于子词的分词
- 2.2 词规范化
- 2.2.1 大小写折叠
- 2.2.2 词目还原
- 2.2.3 词干还原
- 2.3 分句
- 2.4 小结
第2章 文本规范化
在自然语言处理的许多任务中,第一步都离不开文本规范化(text normalization)。文本规范化的作用是将使用字符串表示的文本转化为更易于计算机处理的规范形式。文本规范化一般包括3个步骤:分词、词的规范化、分句。本章将分别介绍这3个步骤。
2.1 分词
词是语言的基本单元,人类学习语言的过程也是从理解词开始的。因此显而易见, 自然语言处理的第一步就是分词(tokenization)。分词是将一段以字符序列表示的文本转化成词元(token)序列的过程。将文本转化成多个词元后,就完成了对文本的初步结构化,方便计算机以词元为基本单位对文本进行处理。在自然语言处理中,词元并不一定等同于词。根据不同分词方法的定义,词元可以是字符(character)、子词(subword)、词(word)等。
2.1.1 基于空格与标点符号的分词
在以英语为代表的印欧语系中,大部分语言都使用空格字符来切分词。因此分词的一种非常简单的方式就是基于空格进行分词:
sentence = "I learn natural language processing with dongshouxueNLP, too."tokens = sentence.split(' ')print(f'输入语句:{sentence}')print(f"分词结果:{tokens}")
输入语句:I learn natural language processing with dongshouxueNLP, too.分词结果:['I', 'learn', 'natural', 'language', 'processing', 'with', 'dongshouxueNLP,', 'too.']
从上面的代码可以看到,最简单的基于空格的分词方法无法将词与词后面的标点符号分割。如果标点符号对于后续任务(例如文本分类)并不重要,可以去除这些标点符号后再进一步分词:
#引入正则表达式包import resentence = "I learn natural language processing with dongshouxueNLP, too."print(f'输入语句:{sentence}')#去除句子中的“,”和“.”sentence = re.sub(r'\,|\.','',sentence)tokens = sentence.split(' ')print(f"分词结果:{tokens}")
输入语句:I learn natural language processing with dongshouxueNLP, too.分词结果:['I', 'learn', 'natural', 'language', 'processing', 'with', 'dongshouxueNLP', 'too']
通过上面的代码就可以完成最简单的分词操作。然而,仅仅将标点符号删除往往会造成许多错误,例如:
- 简写——Ph.D.,A.M.,P.M.;
- 本身词带有标点——We're,Let's;
- 价格——¥90.99;
- 日期——2022.08.08;
- 链接——https://www.boyuai.com/;
- 标签——#新闻,#热点话题;
- 电子邮件地址——someone@somewhere.com;
如果仅仅将标点符号删除,那么上述这些例子中的词就失去了原本的含义。此外,有些时候我们也希望将多个词看作一个词元,例如:New York、Natural Language Processing、Machine Learning。解决这些问题需要用到基于正则表达式的分词方法。
2.1.2 基于正则表达式的分词
2.1.1节提到的许多问题,可以用正则表达式(regular expression)来解决。正则表达式使用单个字符串(通常称为“模式”即pattern)来描述、匹配对应文本中全部匹配某个指定规则的字符串。在文本编辑器中,正则表达式常被用于检索、替换那些匹配某个模式的文本。对于2.1.1节提到的基于空格的分词方法,我们也可以使用正则表达式来实现:
import resentence = "Did you spend $3.4 on arxiv.org for your pre-print?"+\" No, it's free! It's ..."pattern = r"\w+"print(re.findall(pattern, sentence))
['Did', 'you', 'spend', '3', '4', 'on', 'arxiv', 'org', 'for', 'your', 'pre', 'print', 'No', 'it', 's', 'free', 'It', 's']
其中,\w表示匹配a-z,A-Z,0-9和“_”这4种类型的字符,等价于[a-zA-Z0-9_],+表示匹配前面的表达式1次或者多次。因此\w+表示匹配上述4种类型的字符1次或多次。2.1.1节最后提到的许多场景需要保留符号来丰富文本所表达的含义。因此,可以在正则表达式中使用\S来表示除了空格以外的所有字符(\s在正则表达式中表示空格字符,\S则相应的表示\s的补集),将分词正则表达式变为:
pattern = r"\w+|\S\w*"print(re.findall(pattern, sentence))
['Did', 'you', 'spend', '$3', '.4', 'on', 'arxiv', '.org', 'for', 'your', 'pre', '-print', '?', 'No', ',', 'it', "'s", 'free', '!', 'It', "'s", '.', '.', '.']
其中,|表示或运算,*表示匹配前面的表达式0次或多次,\S\w* 表示先匹配除了空格以外的1个字符,后面可以包含0个或多个\w字符。可以看到,目前这样的分词结果仍然还有不理想的地方,在样例中的网址arxiv.org和含有连字符的词pre-print因为符号仍然被分开了。我们可以通过一些特定的模式来解决前面提到的一些基于空格分词难以解决的问题:
1. 匹配可能含有连字符的词
带有连字符的词是最常见的词中带有符号的情况,匹配它的正则表达式模式为:
- 正则表达式模式:\w+([-']\w+)*
- 符合匹配的字符串示例:
- It's, pre-train, fine-tune, pre-print, one-by-one, ...
- 不符合的字符串示例:(下画线表示未匹配到的符号)
- U.S.A.、arxiv.org、$3.4、 ...
- non-、-ly, ...
下面展示代码示例:
pattern = r"\w+(?:[-']\w+)*"print(re.findall(pattern, sentence))
['Did', 'you', 'spend', '3', '4', 'on', 'arxiv', 'org', 'for', 'your', 'pre-print', 'No', "it's", 'free', "It's"]
其中,-表示匹配连字符-,(?:[-']\w+)*表示匹配0次或多次括号内的模式。(?:...)表示匹配括号内的模式,可以和+/*等符号连用。其中?:表示不保存匹配到的括号中的内容,是re代码库中的特殊标准要求的部分。
将前面的匹配符号的模式\S\w*组合起来,可以得到一个既可以处理标点符号又可以处理连字符的正则表达式:
pattern = r"\w+(?:[-']\w+)*|\S\w*"print(re.findall(pattern, sentence))
['Did', 'you', 'spend', '$3', '.4', 'on', 'arxiv', '.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '.', '.', '.']
后续介绍的新模式会和前面提到的模式使用或运算符**|**组合,不再赘述。
2. 匹配简写和网址
在英文简写和网址中,常常会使用'.',它与英文中的句号为同一个符号,匹配这种情况的正则表达式为:
- 正则表达式模式:(\w+\.)+\w+(\.)*
- 符合匹配的字符串示例:
- U.S.A.、arxiv.org
- 不符合的字符串示例:
- $3.4、...
#新的匹配模式new_pattern = r"(?:\w+\.)+\w+(?:\.)*"pattern = new_pattern +r"|"+patternprint(re.findall(pattern, sentence))
['Did', 'you', 'spend', '$3', '.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '.', '.', '.']
需要注意的是,字符“.”在正则表达式中表示匹配任意字符,因此要表示字符本身的含义时,需要在该符号前面加入转义字符(Escape Character)"\",即“\.”。同理,想要表示“+”“?”“(”“)”“$”这些特殊字符时,需要在前面加入转义字符“\”。
3. 货币和百分比
在许多语言中,货币和百分比符号与数字是直接相连的,匹配这种情况的正则表达式为:
- 正则表达式模式:\$?\d+(\.\d+)?%?
- 符合匹配的字符串示例:
- $3.40、3.5%
- 不符合的字符串示例:
- $.4、1.4.0、1%%
#新的匹配pattern,匹配价格符号new_pattern2 = r"\$?\d+(?:\.\d+)?%?"pattern = new_pattern2 +r"|" + new_pattern +r"|"+patternprint(re.findall(pattern, sentence))
['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '.', '.', '.']
其中\d表示所有的数字字符,?表示匹配前面的模式0次或者1次。
4. 英文省略号
省略号本身表达了一定的含义,因此要在分词中将其保留,匹配它的正则表达式为:
- 正则表达式模式:
. . . - 符合匹配的字符串示例:
- ...
#新的匹配pattern,匹配价格符号new_pattern3 = r"\.\.\."pattern = new_pattern3 +r"|" + new_pattern2 +r"|" +\new_pattern +r"|"+patternprint(re.findall(pattern, sentence))
['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '...']
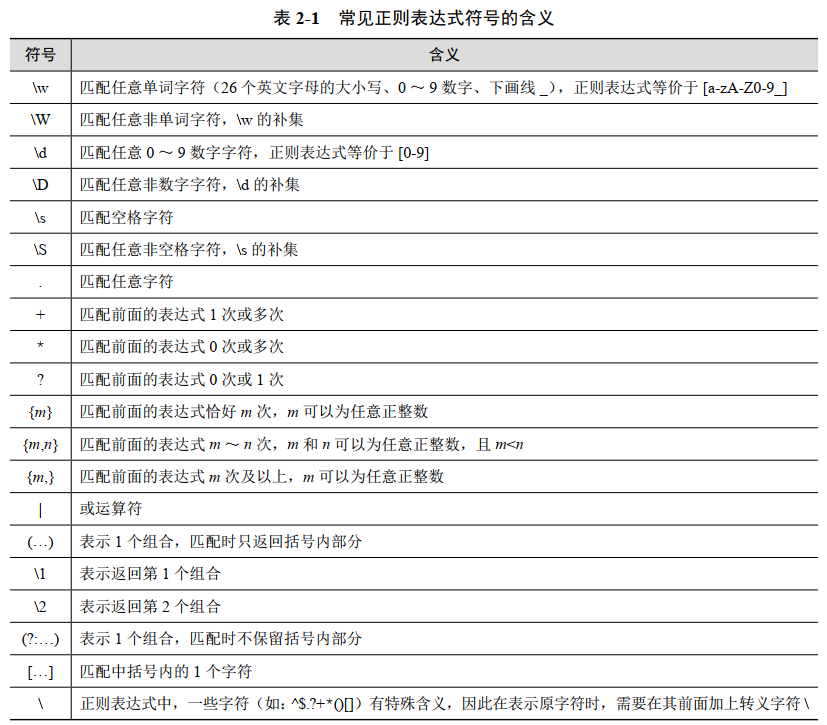
表2-1展示了常见的正则表达式含义的解读,供读者参考。
NLTK是基于Python的NLP工具包,也可以用于实现前面提到的基于正则表达式的分词。
import reimport nltk#引入NLTK分词器from nltk.tokenize import word_tokenizefrom nltk.tokenize import regexp_tokenizetokens = regexp_tokenize(sentence,pattern)print(tokens)
['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '...']
2.1.3 词间不含空格的语言的分词
2.1.1节提到了如英文之类的语言可以通过简单的空格方式进行分词。然而,也有一些词间不加空格的情况,例如汉语、日语、韩语等。此外,即使是像英文这种含空格的语言当中,也有许多情况会包含合成词。例如在推特、微博等社交媒体的标签(例如“#NaturalLanguageProcessing”之类的标签)。那么如何对这种文本进行分词呢?以中文为例,如果对“南京市长江大桥”进行分词,那么可能的分词结果会有:
(1)南京市/长江/大桥;
(2)南京/市长/江大桥;
(3)南/京/市/长/江/大/桥。
不难看出,分词结果(1)和(2)所表示的含义有所不同,而分词结果3则把句子按字符级别进行拆分。想要达到分词结果1和2,常用方法是基于监督学习的序列标注模型,这会在第9章进行详细讨论。
2.1.4 基于子词的分词
在英文单词当中,有很多词根和词缀本身表达了含义。例如“pre”常常包含了“在……之前”的含义(如prefix含义是前缀),相对的,“post-”包含了“在……之后”的含义(如postprocessing表示后处理)。在自然语言处理中,词元也常常可以是类似于词根词缀这样的子词。目前最常见的3种基于子词的方法分别是:
- 字节对编码(byte-pair encoding,BPE);
- 一元语言建模分词(unigram language modeling tokenization);
- 词片(WordPiece)。
上述的这3种方法,都分为两个步骤来切分子词:
(1)一个词元学习器在大量的训练语料上进行学习,并构建出一个词表(即词元的集合);
(2)给定一句新的句子,分词器会根据总结出的词表进行分词。
本节以BPE为例来讲解基于子词的分词方法是如何进行的。
1. 基于BPE的词元学习器
给定一个词表包含所有的字符(如,{A, B, C, D, ..., a, b, c, d, ...}),词元学习器重复以下步骤来构建词表:
(1)找出在训练语料中最常相连的两个符号,这里称其为“
(2)将新组合的符号“
(3)将训练语料中所有相连的“
(4)重复上述步骤
假设有一个训练语料包含了一些方向和中国的地名的拼音:
nan nan nan nan nan nanjing nanjing beijing beijing beijing beijing beijing beijing dongbei dongbei dongbei bei bei
首先,我们基于空格将语料分解成词元,然后加入特殊符号“_”来作为词尾的标识符,通过这种方式可以更好地去包含相似子串的词语(例如区分al在formal和almost中的区别)。
第一步,根据语料构建初始的词表:
corpus = "nan nan nan nan nan nanjing nanjing beijing beijing "+\"beijing beijing beijing beijing dongbei dongbei dongbei bei bei"tokens = corpus.split(' ')#构建基于字符的初始词表vocabulary = set(corpus)vocabulary.remove(' ')vocabulary.add('_')vocabulary = sorted(list(vocabulary))#根据语料构建词表corpus_dict = {}for token in tokens:key = token+'_'if key not in corpus_dict:corpus_dict[key] = {"split": list(key), "count": 0}corpus_dict[key]['count'] += 1print(f"语料:")for key in corpus_dict:print(corpus_dict[key]['count'], corpus_dict[key]['split'])print(f"词表:{vocabulary}")
语料:5 ['n', 'a', 'n', '_']2 ['n', 'a', 'n', 'j', 'i', 'n', 'g', '_']6 ['b', 'e', 'i', 'j', 'i', 'n', 'g', '_']3 ['d', 'o', 'n', 'g', 'b', 'e', 'i', '_']2 ['b', 'e', 'i', '_']词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o']
第二步,词元学习器通过迭代的方式逐步组合新的符号加入到词表中:
for step in range(9):# 如果想要将每一步的结果都输出,请读者自行将max_print_step改成999max_print_step = 3if step < max_print_step or step == 8:print(f"第{step+1}次迭代")split_dict = {}for key in corpus_dict:splits = corpus_dict[key]['split']# 遍历所有符号进行统计for i in range(len(splits)-1):# 组合两个符号作为新的符号current_group = splits[i]+splits[i+1]if current_group not in split_dict:split_dict[current_group] = 0split_dict[current_group] += corpus_dict[key]['count']group_hist=[(k, v) for k, v in sorted(split_dict.items(), \key=lambda item: item[1],reverse=True)]if step < max_print_step or step == 8:print(f"当前最常出现的前5个符号组合:{group_hist[:5]}")merge_key = group_hist[0][0]if step < max_print_step or step == 8:print(f"本次迭代组合的符号为:{merge_key}")for key in corpus_dict:if merge_key in key:new_splits = []splits = corpus_dict[key]['split']i = 0while i < len(splits):if i+1>=len(splits):new_splits.append(splits[i])i+=1continueif merge_key == splits[i]+splits[i+1]:new_splits.append(merge_key)i+=2else:new_splits.append(splits[i])i+=1corpus_dict[key]['split']=new_splitsvocabulary.append(merge_key)if step < max_print_step or step == 8:print()print(f"迭代后的语料为:")for key in corpus_dict:print(corpus_dict[key]['count'], corpus_dict[key]['split'])print(f"词表:{vocabulary}")print()print('-------------------------------------')
第1次迭代当前最常出现的前5个符号组合:[('ng', 11), ('be', 11), ('ei', 11), ('ji', 8), ('in', 8)]本次迭代组合的符号为:ng迭代后的语料为:5 ['n', 'a', 'n', '_']2 ['n', 'a', 'n', 'j', 'i', 'ng', '_']6 ['b', 'e', 'i', 'j', 'i', 'ng', '_']3 ['d', 'o', 'ng', 'b', 'e', 'i', '_']2 ['b', 'e', 'i', '_']词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng']-------------------------------------第2次迭代当前最常出现的前5个符号组合:[('be', 11), ('ei', 11), ('ji', 8), ('ing', 8), ('ng_', 8)]本次迭代组合的符号为:be迭代后的语料为:5 ['n', 'a', 'n', '_']2 ['n', 'a', 'n', 'j', 'i', 'ng', '_']6 ['be', 'i', 'j', 'i', 'ng', '_']3 ['d', 'o', 'ng', 'be', 'i', '_']2 ['be', 'i', '_']...词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei','ji', 'jing', 'jing_', 'na', 'nan', 'beijing_']-------------------------------------
2. 基于BPE的词元分词器
得到学习到的词表之后,给定一句新的句子,使用BPE词元分词器根据词表中每个符号学到的顺序,贪心地将字符组合起来。例如输入是“nanjing beijing”,那么根据上面例子里的词表,会先把“n”和“g”组合成“ng”,然后组合“be”“bei”……最终分词成:
ordered_vocabulary = {key: x for x, key in enumerate(vocabulary)}sentence = "nanjing beijing"print(f"输入语句:{sentence}")tokens = sentence.split(' ')tokenized_string = []for token in tokens:key = token+'_'splits = list(key)#用于在没有更新的时候跳出flag = 1while flag:flag = 0split_dict = {}#遍历所有符号进行统计for i in range(len(splits)-1):#组合两个符号作为新的符号current_group = splits[i]+splits[i+1]if current_group not in ordered_vocabulary:continueif current_group not in split_dict:#判断当前组合是否在词表里,如果是的话加入split_dictsplit_dict[current_group] = ordered_vocabulary[current_group]flag = 1if not flag:continue#对每个组合进行优先级的排序(此处为从小到大)group_hist=[(k, v) for k, v in sorted(split_dict.items(),\key=lambda item: item[1])]#优先级最高的组合merge_key = group_hist[0][0]new_splits = []i = 0# 根据优先级最高的组合产生新的分词while i < len(splits):if i+1>=len(splits):new_splits.append(splits[i])i+=1continueif merge_key == splits[i]+splits[i+1]:new_splits.append(merge_key)i+=2else:new_splits.append(splits[i])i+=1splits=new_splitstokenized_string+=splitsprint(f"分词结果:{tokenized_string}")
输入语句:nanjing beijing分词结果:['nan', 'jing_', 'beijing_']
2.2 词规范化
所谓词规范化(word normalization)就是指将词或词元变成标准形式的过程,例如:
- 标准化缩写——U.S.A. 和 USA;
- 大写转小写——AI 和 ai、NLP 和 nlp;
- 动词目态转化——am、is、are 和 be;
- 繁体转简体——動手學NLP 和 动手学NLP。
词的规范化是自然语言处理中必不可少的一部分,使词统一成标准格式可以让计算机更容易理解文本,这种方式可以减小词表、删除冗余信息、让词义相近的两个词共享相同的特征表示等好处。
2.2.1 大小写折叠
大小写折叠(case folding)是将所有的英文大写字母转化成小写字母的过程。在搜索场景中,用户往往喜欢使用小写,而在计算机中,大写字母和小写字母并非同一字符,当遇到用户想要搜索一些人名、地名等带有大写字母的专有名词的情况下,正确的搜索结果可能会比较难匹配上。
# Case Foldingsentence = "Let's study Hands-on-NLP"print(sentence.lower())
let's study hands-on-nlp
2.2.2 词目还原
在诸如英文这样的语言中,很多单词都会根据不同的主语、语境、时态等情形修改形态,而这些单词本身表达的含义是接近甚至是相同的。例如英文中的am、is、are都可以还原成be,英文名词cat根据不同情形有cat、cats、cat's、cats'等多种形态。这些形态对文本的语义影响相对较小,但是大幅度提高了词表的大小,因而提高了自然语言处理模型的构建成本。因此在有些文本处理问题上,会将所有的词进行词目还原(lemmatization),即找出词的原型。人类在学习这些语言的过程中,可以通过词典找词的原型;类似地,计算机可以通过建立词典来进行词目还原:
# 构建词典lemma_dict = {'am': 'be','is': 'be','are': 'be','cats': 'cat',\"cats'": 'cat',"cat's": 'cat','dogs': 'dog',"dogs'": 'dog',\"dog's": 'dog', 'chasing': "chase"}sentence = "Two dogs are chasing three cats"words = sentence.split(' ')print(f'词目还原前:{words}')lemmatized_words = []for word in words:if word in lemma_dict:lemmatized_words.append(lemma_dict[word])else:lemmatized_words.append(word)print(f'词目还原后:{lemmatized_words}')
词目还原前:['Two', 'dogs', 'are', 'chasing', 'three', 'cats']词目还原后:['Two', 'dog', 'be', 'chase', 'three', 'cat']
另外,也可以利用NLTK自带的词典来进行词目还原:
import nltk#引入nltk分词器、lemmatizer,引入wordnet还原动词from nltk.tokenize import word_tokenizefrom nltk.stem import WordNetLemmatizerfrom nltk.corpus import wordnet#下载分词包、wordnet包nltk.download('punkt', quiet=True)nltk.download('wordnet', quiet=True)lemmatizer = WordNetLemmatizer()sentence = "Two dogs are chasing three cats"words = word_tokenize(sentence)print(f'词目还原前:{words}')lemmatized_words = []for word in words:lemmatized_words.append(lemmatizer.lemmatize(word, wordnet.VERB))print(f'词目还原后:{lemmatized_words}')
词目还原前:['Two', 'dogs', 'are', 'chasing', 'three', 'cats']词目还原后:['Two', 'dog', 'be', 'chase', 'three', 'cat']
更精确的词目还原基于语素分析(morphological parsing)。在语言学中,语素(morpheme)是语言中最小的有意义或有语法功能的单位。以中文为例,“动”、“手”和“学”这3个语素就组合成了“动手学”这个词。在英文中的情况会有些不一样,英文中很多单词是由词干(stem)和词缀(affix)组成的。词干是表达主要含义的语素,而词缀一般和词干连接,表达了附加的含义。例如unbelievable这个词,是由“un-”(词缀,表示否定)、“believ”(表示believe,词根,表示相信)和“-able”(词缀,表示可能的)组成的,三者合起来的意思是“不可置信的”。想要准确地抽取出词的词根和词干,需要使用到语素分析。我们会在第10章讨论语素分析所涉及的相关技术。
2.2.3 词干还原
词干还原(stemming)是将词变成词干的过程。词干还原是一种简单快速的词目还原的方式,通过将所有的词缀直接移除来获取词干。为了保持词干的完整性,波特词干还原器提出了一套基于改写规则的方法来进行词干还原。例如:
- TIONAL -> TION(例如,conditional -> condition);
- IZATION -> IZE(例如,organization -> organize);
- SSES -> SS(例如,classes -> class)。
如果对这部分有兴趣的话,可以查阅NLTK工具包对于词干还原相关的描述。
2.3 分句
很多实际场景中,我们往往需要处理很长的文本,例如新闻、财报、日志等。让计算机直接同时处理整个文本会非常的困难,因此需要将文本分成许多句子来让计算机分别进行处理。对于分句问题,最常见的方法是根据标点符号来分割文本,例如“!”“?”“。”等符号。然而,在某些语言当中,个别分句符号会有歧义。例如英文中的句号“.”也同时有省略符(例如“Inc.”、“Ph.D.”、“Mr.”等)、小数点(例如“3.5”、“.3%”)等含义。这些歧义会导致分句困难。为了解决这种问题,常见的方案是先进行分词,使用基于正则表达式或者基于机器学习的分词方法将文本分解成词元,随后基于符号判断句子边界。例如:
sentence_spliter = set([".","?",'!','...'])sentence = "Did you spend $3.4 on arxiv.org for your pre-print? " + \"No, it's free! It's ..."tokens = regexp_tokenize(sentence,pattern)sentences = []boundary = [0]for token_id, token in enumerate(tokens):# 判断句子边界if token in sentence_spliter:#如果是句子边界,则把分句结果加入进去sentences.append(tokens[boundary[-1]:token_id+1])#将下一句句子起始位置加入boundaryboundary.append(token_id+1)if boundary[-1]!=len(tokens):sentences.append(tokens[boundary[-1]:])print(f"分句结果:")for seg_sentence in sentences:print(seg_sentence)
分句结果:['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your','pre-print', '?']['No', ',', "it's", 'free', '!']["It's", '...']
2.4 小结
本章介绍了自然语言处理中的文本规范化过程,包含了分词、词的规范化以及分句这3个部分。分词中通过正则表达式的方式,可以将一些属于词元的标点符号给很好地区分出来。词的规范化可以将词元转换成标准形式,从而让计算机更好地去处理这些词元。分句则可以将长文本切分成多个短文本,从而让计算机更好地去处理。本章重点介绍了基于规则方法的文本规范化方式,但也存在很多基于机器学习和神经网络技术的文本规范化方法,相关技术在后续章节中会逐步介绍。